

Embedded Machine Learning
In recent years, we have been experiencing a rapid growth in Artificial Intelligence (AI) and Machine Learning (ML), especially in deep learning and Deep Neural Networks (DNNs) that achieved superhuman levels of accuracy in many tasks such as natural language processing, object detection, speech recognition and more. One topic of our group is embedded machine learning. In general we follow two directions. We apply machine learning (ML) for optimization of embedded systems and we research ML algorithms and hardware to optimize inference and training on embedded systems.
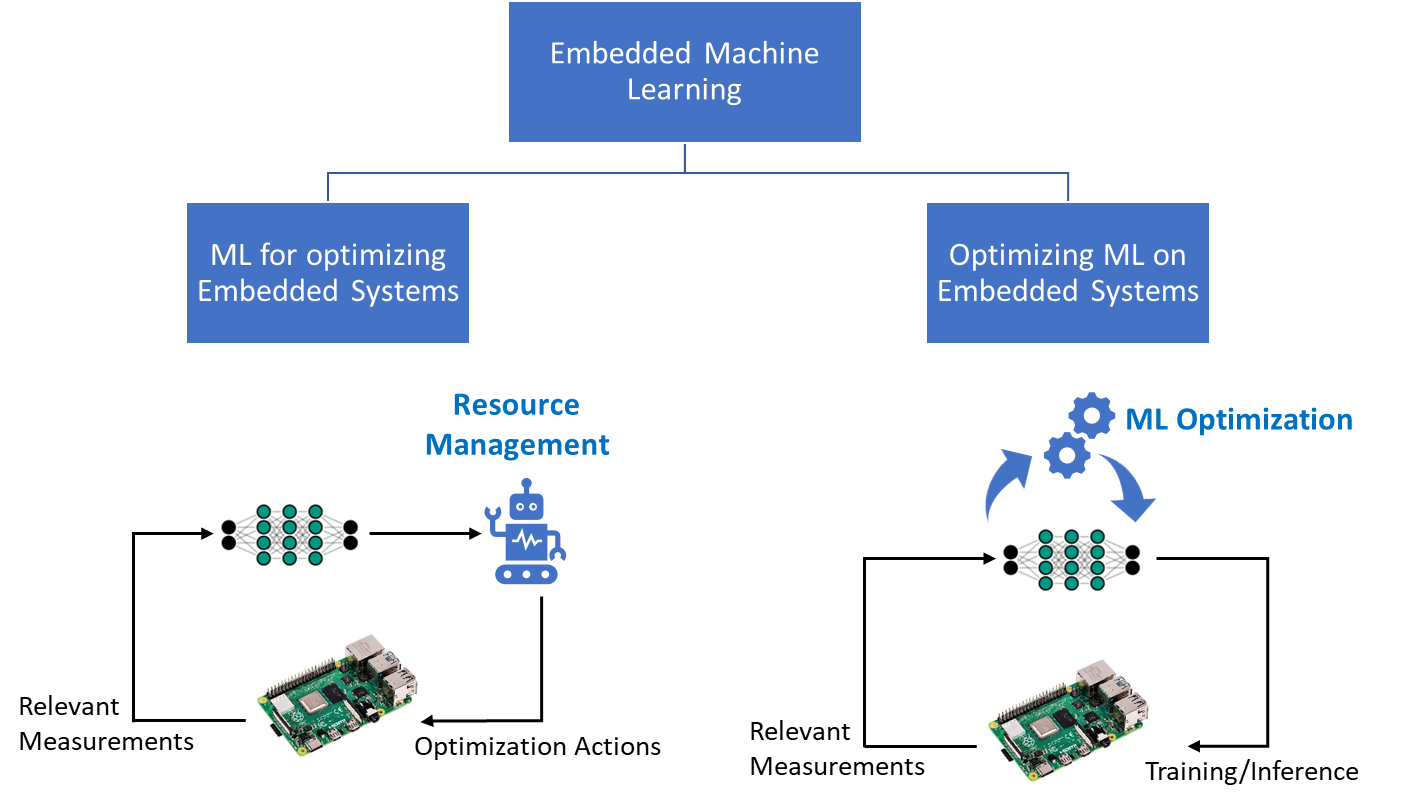
Machine learning for optimization of embedded systems
Sophisticated resource management becomes a pressing need in modern embedded systems, where many connected devices collaborate towards achieving a specific goal and each of these devises may execute several applications. The goal of resource management is to allocate resources to applications while optimizing for system properties, e.g., performance, and satisfying its constraints, e.g., temperature. To achieve full potential for optimization, resource management needs to exploit relevant knowledge about the system with its two parts; hardware and software, within its decision making process.
The CES has developed techniques that employ analytical models and/or design-time profiling to obtain knowledge about the system [1-3]. However, building analytical models is not always feasible due to the high complexity of software and hardware. Machine learning (ML) can tackle these challenges, as we have shown in [4]. At CES, we investigate how machine learning can be used for various aspects of optimization of resource management.
Supervised learning has been used in [5] to build a model that predicts the application sensitivities to voltage and frequency changes in terms of performance and power. This model empowers building a smart boosting technique that is able to maximize the performance under a temperature constraint. In [6], supervised learning has been also used to build a model that predicts the slowdown in the application execution induced by cache contention between applications running on the same cluster. This models enables a resource management technique, which selects application-to-cluster mapping that satisfies the performance constraints of applications. Imitation learning has been employed in [7] to migrate applications to different cores at run time such that the temperature of the chip is minimized while satisfying QoS targets of applications. This work shows that imitation learning enables to use the optimality of an oracle policy, yet at low runtime overhead.
[1] Santiago Pagani, Heba Khdr, Waqaas Munawar, Jian-Jia Chen, Muhammad Shafique, Minming Li, Jörg Henkel, "TSP: Thermal Safe Power - Efficient power budgeting for many-core systems in dark silicon", International Conference on Hardware - Software Codesign and System Synthesis (CODES+ISSS), New Delhi, India, pp. 1-10, 2014.
[2] Heba Khdr, Santiago Pagani, Muhammad Shafique, Jörg Henkel, “Thermal Constrained Resource Management for Mixed ILP-TLP Workloads in Dark Silicon Chips”, in Design Automation Conference (DAC), San Francisco, CA, USA, Jun 7-11 2015.
[3] Heba Khdr, Santiago Pagani, Éricles Sousa, Vahid Lari, Anuj Pathania, Frank Hannig, Muhammad Shafique, Jürgen Teich, Jörg Henkel, “Power density-aware resource management for heterogeneous tiled multicores”, in IEEE Transactions on Computers (TC), Vol.66, Issue 3, Mar 2017.
[4] Martin Rapp, Anuj Pathania, Tulika Mitra, and Jörg Henkel, “Neural Network-based Performance Prediction for Task Migration on S-NUCA Many-Cores”, in IEEE Transactions on Computers (TC), 2020.
[5] Martin Rapp, Mohammed Bakr Sikal, Heba Khdr, and Jörg Henkel. "SmartBoost: Lightweight ML-Driven Boosting for Thermally-Constrained Many-Core Processors" In Design Automation Conference (DAC), pp. 265-270. IEEE, 2021.
[6] Mohammed Bakr Sikal, Heba Khdr, Martin Rapp, and Jörg Henkel. "Thermal- and Cache-Aware Resource Management based on ML-Driven Cache Contention Prediction" In Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2022.
[7] Martin Rapp, Nikita Krohmer, Heba Khdr, and Jörg Henkel. "NPU-Accelerated Imitation Learning for Thermal- and QoS-Aware Optimization of Heterogeneous Multi-Cores" In Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2022.
Contact
Dr. Heba Khdr
Mohammed Bakr Sikal
Benedikt Dietrich
Prof. Dr. Jörg Henkel
Optimization of machine learning for embedded systems
Approximate Inference for embedded systems:
In recent years, the size of neural networks has grown at such a high pace that current hardware cannot keep up with the computational demands. Approximate computing emerged in recent years as a design/computing paradigm that exploits the inherent error resilience of several application domains to deliberately introduce some error in the performed computations but gain in other metrics such as area, power, performance etc [1]. Machine learning applications exhibit error resilience and thus form a perfect candidate for approximate computing [1].
In our chair, we focus on the design of approximate ML accelerators targeting inference on ultra-resource constrained devices [2] as well as more complex DNN accelerators [3]. Specifically, we employ systematic software-hardware co-design approaches in order to achieve low power and/or high performance with minimal accuracy loss [2-3].
References
[1] Giorgos Armeniakos, Georgios Zervakis, Dimitrios Soudris, Jörg Henkel, “Hardware Approximate Techniques for Deep Neural Network Accelerators: A Survey,” ACM Computing Surveys (CSUR), Mar 2022
[2] Konstantinos Balaskas, Georgios Zervakis, Kostas Siozios, Mehdi B. Tahoori, Jörg Henkel, “Approximate Decision Trees For Machine Learning Classification on Tiny Printed Circuits,” International Symposium on Quality Electronic Design (ISQED'22), 6-8 April 2022.
[3] Georgios . Zervakis, Ourania Spantidi, Iraklis Anagnostopoulos, Hussam Amrouch, and Jörg Henkel, “Control Variate Approximation for DNN Accelerators”, Design Automation Conference (DAC), San Francisco, Dec 5-9 2021.
Contact
George Mentzos
Prof. Dr. Jörg Henkel
Distributed training for embedded systems:
The number of devices that autonomously interact with the real world is growing fast, not least because of the rapid growth of the internet of things (IoT). At the same time, there is a trend to keep the data at the edge instead of transferring data to a central server for training. A main reason to do training distributed instead of centralized is the privacy preserving nature of distributed training.
In our chair, we focus on how to enable on-device and distributed learning on resource-constrained heterogeneous devices. Specifically, we are interested how heterogeneous devices can optimally collaborate in distributed training (e.g., in Federated Learning). This problem can be solved on different abstraction levels. Algorithm-level techniques [1,3], for instance, allow more constraint devices to train a suitable sub-model of the large server model. Utilizing both algorithm and hardware-level [2] can further increase the efficiency of such systems (e.g., by using quantization).
References
[1] Martin Rapp, Ramin Khalili, Kilian Pfeiffer, Jörg Henkel. DISTREAL: Distributed Resource-Aware Learning in Heterogeneous Systems. in Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI'22), Vancouver, Canada, Feb 22 - Mar 01 2022.
[2] Kilian Pfeiffer, Martin Rapp, Ramin Khalili, Jörg Henkel. CoCoFL: Communication- and Computation-Aware Federated Learning via Partial NN Freezing and Quantization. in Transactions on Machine Learning Research (TMLR), Jun 2023.
[3] Kilian Pfeiffer, Ramin Khalili, Jörg Henkel. Aggregating Capacity in FL through Successive Layer Training for Computationally-Constrained. Devices in 37th Advances in Neural Information Processing Systems (NeurIPS'23), New Orleans, USA, Dec 10 - 17 (accepted) 2023.
Contact
Mohamed Aboelenien Ahmed
Dr. Heba Khdr
Prof. Dr. Jörg Henkel
CES@![]()
Systems with Non-Volatile Memories
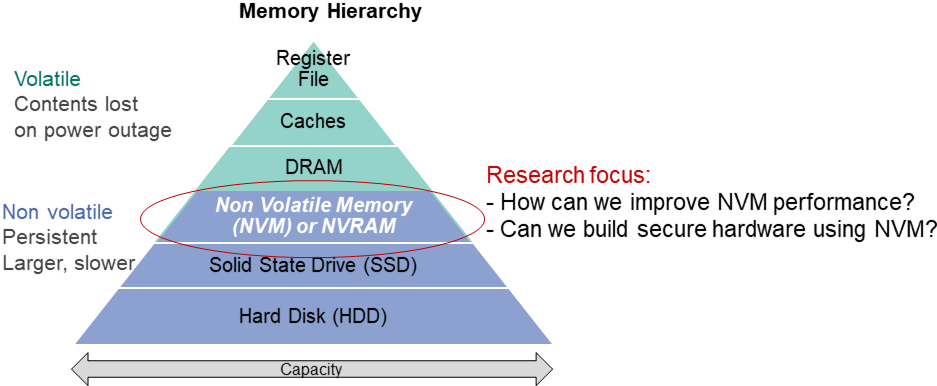
In modern computing systems, DRAM and SRAM memories are volatile and lose data when the power is turned off. To prevent data loss, non-volatile storage solutions like Flash or HDDs are used. However, these storage options are slower. Recently, new non-volatile memory (NVM) technologies have emerged. These new technologies can have speeds closer to DRAMs and have higher density and capacity [1]. When data is written to NVM, it changes the physical properties of the material, such as resistance or magnetic orientation, which are retained even if there is a power outage.
With the benefits of non-volatility and density, NVMs are becoming popular (and their usage is being researched - as caches and main memory). However, their write performance and endurance are significant limiting factors [1-4]. At CES, we are researching low-overhead techniques to mitigate these challenges. We have developed strategies to improve write performance using various write modes (slow, medium, fast) present in NVM memories. The fast mode offers low latency and low write energy, but the data is only retained for a short time, requiring refresh. Slow writes offer higher retention time with a timing and energy consumption overhead. One of our recent ideas, at a high level, is to use fast write for intermediate variables, which have short retention time requirements. Using the above, we demonstrated 20+ percent performance improvement for neural network applications [2].
Furthermore, NVMs can have a wide range of applications, from being an alternative to DRAMs to security. We are also seeing how NVMs can be used in security applications. Interestingly, each NVM device offers a unique ID/fingerprint. This is because when we apply the same writing voltage to different NVM chips, each of them will reach a unique resistance (or physical property) value that can be used as ID. As an illustration, applying 1 volt to 3 PCM chips results in different cell resistances - 0.9, 1.0, 1.1 MΩ depending upon the inhomogeneity in the material, device imperfections, etc. In general, not only is the value unique, but it is also hard to predict as well due to device variations. These unique IDs can be used in various security applications [3].
At CES, we look forward to developing reliable, performance-efficient, secure systems with NVM memories as a key research focus.
References
[1] Jörg Henkel, Lokesh Siddhu, Lars Bauer, Jürgen Teich, Stefan Wildermann, Mehdi Tahoori, Mahta Mayahinia, Jeronimo Castrillon, Asif Ali Khan, Hamid Farzaneh, João Paulo C. de Lima, Jian-Jia Chen, Christian Hakert, Kuan-Hsun Chen, Chia-Lin Yang, Hsiang-Yun Cheng Non-Volatile Memories: Challenges and Opportunities for Embedded System Architectures with Focus on Machine Learning Applications, in International Conference on Compilers, Architectures, and Synthesis for Embedded Systems (CASES), Sep 2023.
[2] Lokesh Siddhu; Hassan Nassar; Lars Bauer; Christian Hakert; Nils Hölscher; Jian-Jia Chen; Jörg Henkel Swift-CNN: Leveraging PCM Memory’s Fast Write Mode to Accelerate CNNs, IEEE Embedded Systems Letters, Dec 2023.
[3] Hassan Nassar, Lars Bauer, Jörg Henkel ANV-PUF: Machine-Learning-Resilient NVM-Based Arbiter PUF, Transactions on Embedded Computing Systems (TECS), ESWEEK23 Special Edition, Sep 2023.
[4] Nils Hölscher, Christian Hakert, Hassan Nassar, Kuan-Hsun Chen, Lars Bauer, Jian-Jia Chen, and Jörg Henkel Memory Carousel: LLVM-Based Bitwise Wear-Leveling for Non-Volatile Main Memory in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD, Volume 42, Issue 8), Aug 2023.
[5] Miran Tobar, Hassan Nassar, Jörg Henkel REPAIR: Reliability Enhancement of NVM FPGAs through Lifetime-Aware Differential Partial Reconfiguration in Design Automation Conference (DAC), California, USA, Jul 26 - 29 2026.
[6] Miran Tobar, Hassan Nassar, Jörg Henkel Cross-Layer Security Through Multi-Level Cell Memories from Hardware Obfuscation to AI Model Protection in International Symposium on Quality Electronic Design (ISQED'26), San Francisco, California, USA, Apr 08 - 10 2026.
[7] Hassan Nassar, Ming-Liang Wei, Chia-Lin Yang, Jörg Henkel and Kuan-Hsun Chen REAP-NVM: Resilient Endurance-Aware NVM-based PUF against Learning-based Attacks Design, Automation and Test in Europe Conference (DATE), Lyon, France, Mar 31 - Apr 2 2025.
[8] Jörg Henkel, Lokesh Siddhu, Hassan Nassar, Lars Bauer, Jian-Jia Chen, Christian Hakert, Tristan Seidl, Kuan-Hsun Chen, Xiaobo Sharon Hu, Mengyuan Li, Chia-Lin Yang, and Ming-Liang Wei Co-Designing NVM-based Systems for Machine Learning and In-memory Search Applications in International Conference on Computer-Aided Design (ICCAD), Oct 27-31 2024.
[9] Christian Hakert, Kuan-Hsun Chen, Horst Schirmeier, Lars Bauer, Paul R. Genssler, Georg von der Brüggen, Hussam Amrouch, Jörg Henkel, Jian-Jia Chen Software-Managed Read and Write Wear-Leveling for Non-Volatile Main Memory in ACM Transactions on Embedded Computing Systems (Volume 21, Issue 1), Jan 2022.
[10] Mina Ibrahim, Martel Shokry, Lokesh Siddhu, Lars Bauer, Hassan Nassar and Jörg Henkel An FPGA-Based RISC-V Instruction Set Extension and Memory Controller for Multi-Level Cell NVM 2024 International Conference on Microelectronics (ICM), Doha, Qatar, Dec 14-17 2024.
Contact
Dr. Hassan Nassar
Prof. Dr. Jörg Henkel
CES@![]()
Cross-layer Security in Emerging Systems
Security is a critical component in the modern computing environment. In the current era of the Internet of Things (IoT), systems are becoming increasingly interconnected on different emerging applications, powered by improved network capabilities in recent communication technologies such as 5G. Among these applications are Artificial Intelligence (AI) applications, Edge-, and Cloud Computing.
These interconnected systems are vulnerable to new attack vectors that combine hardware and software resources to exploit the devices in unexpected ways.
In our chair, we target the security of such systems from a cross-layer perspective i.e., both in software and hardware domains.
Our focus is on new attacks whether physical or remote, as well as detection mechanisms and other countermeasures, considering the effects of such techniques on the overall security and the system’s performance.
Some of our current topics of interest are the following:
- Covert- and side-channel attacks and mitigation [1-4]
- Machine-learning-based attack detection techniques [4,9]
- Security of cloud FPGAs and emerging memory architectures [5-8]
- Acceleration of post-quantum cryptography
- Attestation and code integrity verification [9]
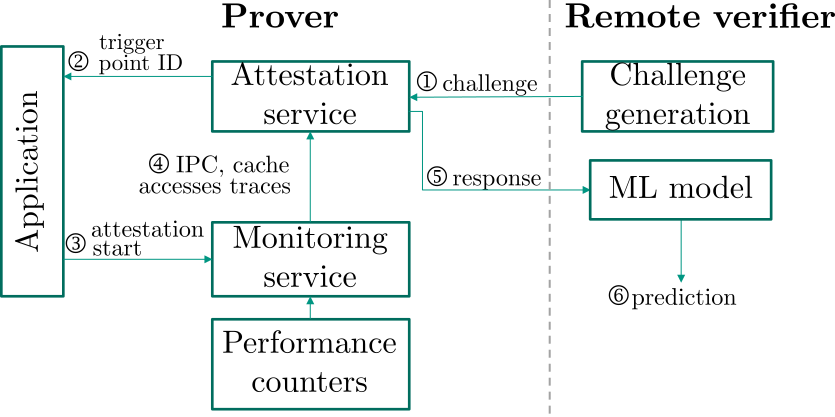
As an example, in a recent work [9] we proposed an ML-based hardware-assisted lightweight remote attestation scheme that leverages the application’s dynamic execution metrics as features for an anomaly detection approach. By doing so, we are able to correctly classify cases where an application is maliciously infected by an attacker and thus ensure dynamic the integrity of the application.
References
[1] Jeferson Gonzalez-Gomez, Lars Bauer, Jörg Henkel, “Cache-based Side-Channel Attack Mitigation for Many-core Distributed Systems via Dynamic Task Migration” in IEEE Transactions on Information Forensics and Security (TIFS), Apr 2023.
[2] Hassan Nassar, Simon Pankner, Lars Bauer, Jörg Henkel, “Configurable Ring Oscillators as a Side-Channel Countermeasure” in 60th Design Automation Conference (DAC), San Francisco, Jul 9-13 2023.
[3] Jeferson Gonzalez-Gomez, Kevin Cordero-Zuñiga, Lars Bauer, Jörg Henkel, “The First Concept and Real-world Deployment of a GPU-based Thermal Covert Channel: Attack and Countermeasures” in 26th Design, Automation and Test in Europe Conference (DATE'23), Antwerp, Belgium, Apr 17-19 2023.
[4] Jeferson Gonzalez-Gomez, Mohammed Bakr Sikal, Heba Khdr, Lars Bauer, Jörg Henkel, “Smart Detection of Obfuscated Thermal Covert Channel Attacks in Many-core Processors” in 60th Design Automation Conference (DAC), San Francisco, Jul 9-13 2023.
[5] Mohamed Alsharkawy, Hassan Nassar, Jeferson González-Gómez, Xun Xiao, Osama Abboud, and Jörg Henkel DPReF: Decentralized Key Generation Using Physical-Related Functions in ACM Transactions on Embedded Computing Systems (Volume 24, Issue 5s), Sep 2025.
[6] Hassan Nassar, Lars Bauer, and Jörg Henkel, “CaPUF: Cascaded PUF Structure for Machine Learning Resiliency” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD, Volume 41, Issue 11), Nov 2022.
[7] Hassan Nassar, Hanna AlZughbi, Dennis Gnad, Lars Bauer, Mehdi Tahoori and Jörg Henkel, “LoopBreaker: Disabling Interconnects to Mitigate Voltage-Based Attacks in Multi-Tenant FPGAs” in IEEE/ACM 40th International Conference On Computer Aided Design (ICCAD), Virtual Conference, 1-5 2021.
[8] Hassan Nassar, Lars Bauer and Jörg Henkel “TiVaPRoMi: Time-Varying Probabilistic Row-Hammer Mitigation” in IEEE/ACM 24th Design, Automation and Test in Europe Conference (DATE'21), Virtual Conference, Feb 1-5 2021.
[9] Jeferson Gonzalez-Gomez, Hassan Nassar, Lars Bauer, Jörg Henkel, “LightFAt: Mitigating Control-flow Explosion via Lightweight PMU-based Control-Flow Attestation” in 2024 IEEE International Symposium on Hardware Oriented Security and Trust (HOST).
[10] Mohamed Alsharkawy, Mohamed Aboelenien Ahmed, Hassan Nassar, Jeferson Gonzalez, Heba Khdr, Osama Abboud, Xun Xiao, Jörg Henkel TrustSeed: Lightweight Attestation Protocol for Ensuring LLM Integrity in DATE 2026, Verona, Apr 20 - 22 2026.
Contact
Dr. Hassan Nassar
Prof. Dr. Jörg Henkel
CES@![]()
Adaptive and Self-Organizing On-Chip Systems
Embedded systems are no longer designed and dedicated to a specific and narrow use case. Instead, they are often expected to provide a large degree of flexibility, for instance, users of handhelds can download and start new applications on demand. These requirements can be addressed at different levels for embedded multi-/many core systems, i.e. the processor level and the system level. The main goal of this group is to investigate adaptivity at these levels in order to:
- increase the performance to fulfill the user's expectations or constraints
- increase the efficiency, e.g. ‘performance per area' or ‘performance per energy'
- increase the reliability, i.e. the correct functionality of the system needs to be tested regularly and if
a component is faulty it needs to be repaired (e.g. by using redundancy) or avoided (i.e. not used any more)
 At the processor level, this group investigates processor microarchitectures (e.g. caches and execution control) and different types of reconfigurable processors (allow changing parts of their hardware at run time). Reconfigurable processors can be realized by hardware structures that are used in FPGAs (field-programmable gate arrays) as they allow changing parts of the FPGA configuration at run time. These run-time reconfigurable processors are often used to provide application-specific accelerators on demand. A run-time system is used to decide which accelerators shall be reconfigured, which is especially challenging in multi-tasking and multi-core scenarios. Run-time reconfiguration can also be used to improve the reliability of a system, which is important in environments with a high radiation (space missions) and for devices that are built using unreliable manufacturing processes (as observed and predicted for upcoming nanometer technology nodes). Here, run-time reconfiguration can help to test the functionality of the underlying hardware, to correct temporary faults, and to adapt to permanents faults. In addition to microarchitectures and run-time systems, also compiler support for reconfigurable processors is investigated to enable a programmer-friendly access to the concepts of reconfigurable processors.
At the processor level, this group investigates processor microarchitectures (e.g. caches and execution control) and different types of reconfigurable processors (allow changing parts of their hardware at run time). Reconfigurable processors can be realized by hardware structures that are used in FPGAs (field-programmable gate arrays) as they allow changing parts of the FPGA configuration at run time. These run-time reconfigurable processors are often used to provide application-specific accelerators on demand. A run-time system is used to decide which accelerators shall be reconfigured, which is especially challenging in multi-tasking and multi-core scenarios. Run-time reconfiguration can also be used to improve the reliability of a system, which is important in environments with a high radiation (space missions) and for devices that are built using unreliable manufacturing processes (as observed and predicted for upcoming nanometer technology nodes). Here, run-time reconfiguration can help to test the functionality of the underlying hardware, to correct temporary faults, and to adapt to permanents faults. In addition to microarchitectures and run-time systems, also compiler support for reconfigurable processors is investigated to enable a programmer-friendly access to the concepts of reconfigurable processors.
For multi-/many core systems as e.g. Intel's Single-chip Cloud Computer (SCC, providing 48 Pentium-like cores on one chip) or even larger systems, the question arises how these systems can be managed in an efficient way. For instance, the decisions ‘which application obtains how many cores' and ‘on which cores it shall execute' are crucial for performance and efficiency. A run-time system is required that scales with the number of cores and the number of applications that shall execute. Among others, it needs to consider the communication between the applications, the available memory bandwidth, or the temperature of the cores. Strategies that are based on distributed components that negotiate with each other (so-called Agents) are investigated for maintaining scalability and flexibility.
References
[1] Hassan Nassar, Martin Rapp, Lars Bauer, Mostafa Elshimy, Zeynep Guelbeyaz Demirdag, Jörg Henkel MIQARA: Mixed-Criticality Queue-based Architecture for Reconfigurable Accelerator Platforms in DATE 2026, Verona,
Apr 20 - 22 2026.
[2] Hassan Nassar, Lars Bauer and Jörg Henkel Turbo-FHE: Accelerating Fully Homomorphic Encryption with FPGA and HBM Integration IEEE Design and Test Magazine, (Volume 42, Issue 3) 2025.
[3] Jayeeta Chaudhuri, Hassan Nassar, Dennis R.E. Gnad, Jörg Henkel, Mehdi B. Tahoori, and Krishnendu Chakrabarty Hacking the Fabric: Targeting Partial Reconfiguration for Fault Injection in FPGA Fabrics in The 33rd IEEE Asian Test Symposium (ATS 2024), Ahmedabad, Gujarat, India, Dec 17-20 2024.
[4] Mohamed Aboelenien Ahmed, Mohamed Alsharkawy, Simon Bothe, Hassan Nassar, Lars Bauer, Jörg Henkel FPGA Acceleration of Homomorphic Encryption Assisted Federated Learning in Journal of Circuits, Systems, and Computers, just accepted 2026.
[5] Hassan Nassar, Rafik Youssef, Lars Bauer, and Jörg Henkel Supporting Dynamic Control-Flow Execution for Runtime Reconfigurable Processors in IEEE International Conference on Microelectronics (ICM), Abu Dhabi, UAE, Dec 17-20 2023.
[6] Hassan Nassar, Lars Bauer, Jörg Henkel Effects of Runtime Reconfiguration on PUFs Implemented as FPGA-based Accelerators in Embedded Systems Letters (ESL), ESWEEK23 Special Edition (Volume 15, Issue 4), Dec 2023.
[7] Marcel Mettler, Martin Rapp, Heba Khdr, Daniel Mueller-Gritschneder, Jörg Henkel An FPGA-based Approach to Evaluate Thermal and Resource Management Strategies of Many-Core Processors in ACM Transactions on Architecture and Code Optimization (Volume 19, Issue 3), Sep 2022.
[8] Veera Venkata Ram Murali Krishna Rao Muvva, Martin Rapp, Jörg Henkel, Hussam Amrouch, Marilyn Wolf On the Effectiveness of Quantization and Pruning on the Performance of FPGAs-based NN Temperature Estimation in 2021 ACM/IEEE 3rd Workshop on Machine Learning for CAD (MLCAD), 30 Aug - 03 Sep 2021.
[9] Ahmed Ossairy, Hassan Nassar, Jörg Henkel, Atef Afifi, Mohamed A. Abd El Ghany A High-Speed, Area-Efficient FPGA Accelerator for the A* Algorithm in International Conference on Mechatronics and Robotics Engineering (ICMRE 2026), Oldenburg, Germany, Mar 2 - 4 2026.
[10] Hassan Nassar, Philipp Machauer, Lars Bauer, Dennis Gnad, Mehdi Tahoori and Jörg Henkel DoS-FPGA: Denial of Service on Cloud FPGAs via Coordinated Power Hammering in International Conference on Computer Aided Design (ICCAD), Oct 27-31 2024.
Contact
Dr. Hassan Nassar
Zeynep Demirdag
CES@![]()